
Databricks stellt OfficeQA vor: Benchmark zum Testen von Grounded Reasoning bei KI-Tools
15.12.2025
Databricks hat OfficeQA entwickelt und Open Source bereit gestellt, einen Benchmark zum Testen von Grounded Reasoning bei KI-Tools anhand wirtschaftlich wertvoller und realitätsnaher Aufgaben im Unternehmensbereich. Grounded Reasoning umfasst die Beantwortung von Fragen auf der Grundlage komplexer proprietärer Datensätze, die unstrukturierte Dokumente und tabellarische Daten enthalten, wie sie üblicherweise in Unternehmen verwendet werden.
Es gibt bereits mehrere Benchmarks, die die Grenzen der Fähigkeiten von KI-Agenten ausloten (GDPval, Humanity's Last Exam (HLE), ARC-AGI-2), aber die Forscher von Databricks halten sie nicht für repräsentativ für die Arten von Aufgaben, die für Unternehmen auf Unternehmensebene wichtig sind. OfficeQA schließt diese Lücke.
Databricks hatte bei der Entwicklung von OfficeQA mehrere wichtige Ziele. Erstens sollten die Fragen anspruchsvoll sein, weil sie sorgfältige Arbeit erfordern – Präzision, Sorgfalt und Zeit – und nicht, weil sie Fachwissen auf Doktorandenebene erfordern. Zweitens muss jede Frage eine einzige, eindeutig richtige Antwort haben, die automatisch anhand der Grundwahrheit überprüft werden kann, damit die Systeme ohne menschliche oder LLM-Beurteilung trainiert und bewertet werden können. Und schließlich, was am wichtigsten ist, sollte der Benchmark die häufigsten Probleme, mit denen Unternehmenskunden konfrontiert sind, genau widerspiegeln.
Databricks hat häufige Unternehmensprobleme in drei Hauptkomponenten zusammengefasst:
- Komplexität von Dokumenten: Unternehmen verfügen über große Sammlungen von Quellmaterialien – wie Scans, PDFs oder Fotos –, die oft umfangreiche numerische oder tabellarische Daten enthalten.
- Informationsabruf und -aggregation: Sie müssen Informationen in vielen solchen Dokumenten effizient suchen, extrahieren und kombinieren.
- Analytisches Denken und Beantwortung von Fragen: Sie benötigen Systeme, die in der Lage sind, Fragen zu beantworten und Analysen auf der Grundlage dieser Dokumente durchzuführen, wobei manchmal Berechnungen oder externes Wissen erforderlich sind.
Viele Unternehmen verlangen bei der Ausführung dieser Aufgaben eine extrem hohe Präzision. „Fast richtig” reicht nicht aus. Eine Abweichung von einer Produkt- oder Rechnungsnummer kann katastrophale Folgen haben. Eine Umsatzprognose mit einer Abweichung von fünf Prozent kann zu dramatisch falschen Geschäftsentscheidungen führen.
Erstellung des Benchmarks
OfficeQA besteht aus 246 Fragen, die je nach der Leistung bestehender KI-Systeme bei der Beantwortung dieser Fragen in zwei Schwierigkeitsgrade unterteilt sind: leicht und schwer. „Leichte” Fragen sind definiert als Fragen, die beide Frontier-Agent-Systeme richtig beantwortet haben, und „schwierige” Fragen sind Fragen, die mindestens einer der Agenten falsch beantwortet hat. Es basiert auf den U.S. Treasury Bulletins, einem Korpus von fast 89.000 Seiten, der sich über acht Jahrzehnte erstreckt. Dadurch wurde ein anspruchsvoller Testbereich geschaffen, in dem KI-Agenten komplexe Tabellen analysieren, Informationen aus vielen Dokumenten abrufen und analytische Schlussfolgerungen mit hoher Präzision ziehen müssen.
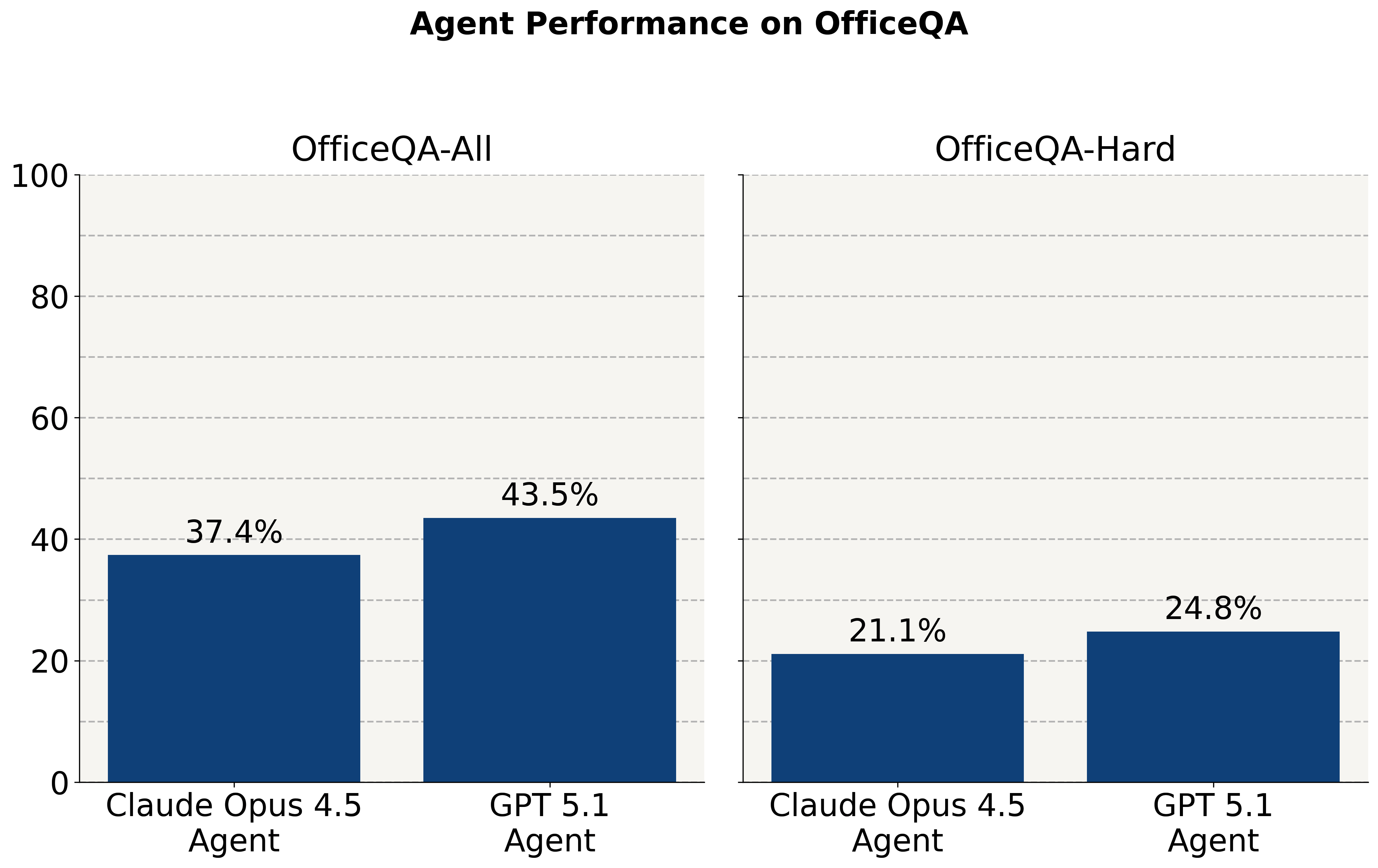
Die Forscher verwendeten bestehende KI-Agentenlösungen wie den GPT-5.1-Agenten mit der Dateisuch- und -abruf-API von OpenAI und einen Claude Opus 4.5-Agenten mit dem Agent SDK von Claude und testeten sie. Obwohl die Frontier-Modelle bei Fragen im Olympiade-Stil gut abschneiden, stellt Databricks fest, dass sie bei diesen wirtschaftlich wichtigen Aufgaben immer noch Schwierigkeiten haben. Ohne Zugriff auf den Datenbestand der U.S. Treasury bulletins beantworten sie etwa zwei Prozent der Fragen richtig. Wenn ihnen ein Korpus von PDF-Dokumenten zur Verfügung gestellt wird, erzielen die KI-Agenten eine Genauigkeit von weniger als 45 Prozent bei allen Fragen und weniger als 25 Prozent bei einer Untergruppe der schwierigsten Fragen.
Die vollständigen Ergebnisse sind hier zusammengefasst: https://www.databricks.com/blog/introducing-officeqa-benchmark-end-to-end-grounded-reasoning
Während der Tests beobachteten die Forscher mehrere häufige Fehlerquellen:
- Parsing-Fehler bleiben eine grundlegende Herausforderung – komplexe Tabellen mit verschachtelten Spaltenhierarchien, zusammengeführten Zellen und ungewöhnlichen Formatierungen führen oft zu falsch ausgerichteten oder falsch extrahierten Werten.
- Mehrdeutige Antworten stellen ebenfalls eine Schwierigkeit dar: Finanzdokumente wie die U.S. Treasury bulletins werden häufig überarbeitet und neu herausgegeben, was bedeutet, dass es für denselben Datenpunkt mehrere legitime Werte geben kann, je nachdem, auf welches Veröffentlichungsdatum sich der KI-Agent bezieht. KI-Agenten beenden die Suche oft, sobald sie eine plausible Antwort gefunden haben, und übersehen dabei die maßgeblichste oder aktuellste Quelle, obwohl sie aufgefordert werden, die neuesten Werte zu finden.
- Das visuelle Verständnis stellt eine weitere erhebliche Lücke dar. Etwa drei Prozent der OfficeQA-Fragen beziehen sich auf Diagramme, Grafiken oder Abbildungen, die visuelles Denken erfordern.
Der OfficeQA-Benchmark ist ein wichtiger Schritt zur Bewertung von KI-Agenten bei wirtschaftlich wertvollen, realitätsnahen Denkaufgaben. Diese verbleibenden Fehlerquellen zeigen, dass noch Forschungsfortschritte erforderlich sind, bevor KI-Agenten das gesamte Spektrum der unternehmensinternen Denkaufgaben bewältigen können.
Der OfficeQA-Benchmark steht der Forschungsgemeinschaft kostenlos zur Verfügung und kann hier abgerufen werden: https://github.com/databricks/officeqa/tree/main
Grounded Reasoning Cup 2026
Databricks startet im Frühjahr 2026 außerdem den Grounded Reasoning Cup, um zu sehen, wer die besten Ergebnisse beim OfficeQA-Benchmark erzielen kann. Interessierte Teams, die teilnehmen möchten, finden weitere Informationen hier: https://surveys.training.databricks.com/jfe/form/SV_0j2jiptb5fD3sF0
Databricks stellt OfficeQA vor: Benchmark zum Testen von Grounded Reasoning bei KI-Tools
15.12.2025
Databricks hat OfficeQA entwickelt und Open Source bereit gestellt, einen Benchmark zum Testen von Grounded Reasoning bei KI-Tools anhand wirtschaftlich wertvoller und realitätsnaher Aufgaben im Unternehmensbereich. Grounded Reasoning umfasst die Beantwortung von Fragen auf der Grundlage komplexer proprietärer Datensätze, die unstrukturierte Dokumente und tabellarische Daten enthalten, wie sie üblicherweise in Unternehmen verwendet werden.
Es gibt bereits mehrere Benchmarks, die die Grenzen der Fähigkeiten von KI-Agenten ausloten (GDPval, Humanity's Last Exam (HLE), ARC-AGI-2), aber die Forscher von Databricks halten sie nicht für repräsentativ für die Arten von Aufgaben, die für Unternehmen auf Unternehmensebene wichtig sind. OfficeQA schließt diese Lücke.
Databricks hatte bei der Entwicklung von OfficeQA mehrere wichtige Ziele. Erstens sollten die Fragen anspruchsvoll sein, weil sie sorgfältige Arbeit erfordern – Präzision, Sorgfalt und Zeit – und nicht, weil sie Fachwissen auf Doktorandenebene erfordern. Zweitens muss jede Frage eine einzige, eindeutig richtige Antwort haben, die automatisch anhand der Grundwahrheit überprüft werden kann, damit die Systeme ohne menschliche oder LLM-Beurteilung trainiert und bewertet werden können. Und schließlich, was am wichtigsten ist, sollte der Benchmark die häufigsten Probleme, mit denen Unternehmenskunden konfrontiert sind, genau widerspiegeln.
Databricks hat häufige Unternehmensprobleme in drei Hauptkomponenten zusammengefasst:
- Komplexität von Dokumenten: Unternehmen verfügen über große Sammlungen von Quellmaterialien – wie Scans, PDFs oder Fotos –, die oft umfangreiche numerische oder tabellarische Daten enthalten.
- Informationsabruf und -aggregation: Sie müssen Informationen in vielen solchen Dokumenten effizient suchen, extrahieren und kombinieren.
- Analytisches Denken und Beantwortung von Fragen: Sie benötigen Systeme, die in der Lage sind, Fragen zu beantworten und Analysen auf der Grundlage dieser Dokumente durchzuführen, wobei manchmal Berechnungen oder externes Wissen erforderlich sind.
Viele Unternehmen verlangen bei der Ausführung dieser Aufgaben eine extrem hohe Präzision. „Fast richtig” reicht nicht aus. Eine Abweichung von einer Produkt- oder Rechnungsnummer kann katastrophale Folgen haben. Eine Umsatzprognose mit einer Abweichung von fünf Prozent kann zu dramatisch falschen Geschäftsentscheidungen führen.
Erstellung des Benchmarks
OfficeQA besteht aus 246 Fragen, die je nach der Leistung bestehender KI-Systeme bei der Beantwortung dieser Fragen in zwei Schwierigkeitsgrade unterteilt sind: leicht und schwer. „Leichte” Fragen sind definiert als Fragen, die beide Frontier-Agent-Systeme richtig beantwortet haben, und „schwierige” Fragen sind Fragen, die mindestens einer der Agenten falsch beantwortet hat. Es basiert auf den U.S. Treasury Bulletins, einem Korpus von fast 89.000 Seiten, der sich über acht Jahrzehnte erstreckt. Dadurch wurde ein anspruchsvoller Testbereich geschaffen, in dem KI-Agenten komplexe Tabellen analysieren, Informationen aus vielen Dokumenten abrufen und analytische Schlussfolgerungen mit hoher Präzision ziehen müssen.
Die Forscher verwendeten bestehende KI-Agentenlösungen wie den GPT-5.1-Agenten mit der Dateisuch- und -abruf-API von OpenAI und einen Claude Opus 4.5-Agenten mit dem Agent SDK von Claude und testeten sie. Obwohl die Frontier-Modelle bei Fragen im Olympiade-Stil gut abschneiden, stellt Databricks fest, dass sie bei diesen wirtschaftlich wichtigen Aufgaben immer noch Schwierigkeiten haben. Ohne Zugriff auf den Datenbestand der U.S. Treasury bulletins beantworten sie etwa zwei Prozent der Fragen richtig. Wenn ihnen ein Korpus von PDF-Dokumenten zur Verfügung gestellt wird, erzielen die KI-Agenten eine Genauigkeit von weniger als 45 Prozent bei allen Fragen und weniger als 25 Prozent bei einer Untergruppe der schwierigsten Fragen.
Die vollständigen Ergebnisse sind hier zusammengefasst: https://www.databricks.com/blog/introducing-officeqa-benchmark-end-to-end-grounded-reasoning
Während der Tests beobachteten die Forscher mehrere häufige Fehlerquellen:
- Parsing-Fehler bleiben eine grundlegende Herausforderung – komplexe Tabellen mit verschachtelten Spaltenhierarchien, zusammengeführten Zellen und ungewöhnlichen Formatierungen führen oft zu falsch ausgerichteten oder falsch extrahierten Werten.
- Mehrdeutige Antworten stellen ebenfalls eine Schwierigkeit dar: Finanzdokumente wie die U.S. Treasury bulletins werden häufig überarbeitet und neu herausgegeben, was bedeutet, dass es für denselben Datenpunkt mehrere legitime Werte geben kann, je nachdem, auf welches Veröffentlichungsdatum sich der KI-Agent bezieht. KI-Agenten beenden die Suche oft, sobald sie eine plausible Antwort gefunden haben, und übersehen dabei die maßgeblichste oder aktuellste Quelle, obwohl sie aufgefordert werden, die neuesten Werte zu finden.
- Das visuelle Verständnis stellt eine weitere erhebliche Lücke dar. Etwa drei Prozent der OfficeQA-Fragen beziehen sich auf Diagramme, Grafiken oder Abbildungen, die visuelles Denken erfordern.
Der OfficeQA-Benchmark ist ein wichtiger Schritt zur Bewertung von KI-Agenten bei wirtschaftlich wertvollen, realitätsnahen Denkaufgaben. Diese verbleibenden Fehlerquellen zeigen, dass noch Forschungsfortschritte erforderlich sind, bevor KI-Agenten das gesamte Spektrum der unternehmensinternen Denkaufgaben bewältigen können.
Der OfficeQA-Benchmark steht der Forschungsgemeinschaft kostenlos zur Verfügung und kann hier abgerufen werden: https://github.com/databricks/officeqa/tree/main
Grounded Reasoning Cup 2026
Databricks startet im Frühjahr 2026 außerdem den Grounded Reasoning Cup, um zu sehen, wer die besten Ergebnisse beim OfficeQA-Benchmark erzielen kann. Interessierte Teams, die teilnehmen möchten, finden weitere Informationen hier: https://surveys.training.databricks.com/jfe/form/SV_0j2jiptb5fD3sF0